A következőkban azt a kérdést járjuk körül, hogy a mesterséges intelligencia (MI) hogyan hat az ízlésünkre: a poszt középpontjában a külföldi és magyar piac jelenleg legnépszerűbb streaming szolgáltatója, a Netflix áll. Rendkívül érdekes, hogy hogyan tematizálja és alakítja át a streaming a televíziózást, és az, hogy a legnagyobb szolgáltató milyen eszközökhöz nyúl annak érdekében, hogy a nézők egyre jobb eszközökön, egyre inkább a nekik tetsző műsorokat nézhessenek. Ez a jelenség több tudományterületet is érint, ezért szociológiai, gazdasági és technológiai szemüvegen keresztül is vizsgáljuk majd Netflixet és a felhasználókra gyakorolt hatását. Célunk, hogy láthatóvá váljon az emberi döntéshozás „meghekkelése”, médiafogyasztásunk átalakulása, illetve az esztétikai érzetünk befolyásolásának képessége és lehetősége.
A „modern kor hatalma” maga az algoritmus. A biotechnológia és információs technológia összeolvadásából olyan algoritmusok születnek, amelyek szinte jobban megértik az érzéseinket, mint mi saját magunkat. A hatalmunk, vagyis a választásunk szabadsága pedig innentől kezdve már nem feltétlenül a mi kezünkben lesz. A MI-val kéz a kézben járó biometrikus szenzorok és a big data algoritmusok meghekkelhetik érzéseinket, vágyainkat, és pontosan tudni fogják mindazt, amit mi sem tudunk saját magunkról: hogy kik is vagyunk valójában, és hogy mit is akarunk. Egy algoritmus mindezek mellett abban is segíthet, hogy érdeklődési körünk alapján melyik filmet nézzük meg, de a szem és arcizmok mozgását követve képes lehet az emberek érzelmeit is felismerni, pont úgy, ahogy azt Kínában élő emberek tapasztalják a digitális diktatúrában.
Egy kezdetben DVD árusításával foglalkozó amerikai cég az MI által használt technikákat gyűjtötte össze, és integrálta egy közös rendszerbe. Ez, a már-már tökélyre fejlesztett rendszer az, amit ma Netflix-ként ismerünk – és ami befolyásolja az esztétikai érzékünket, ha úgy tetszik, az ízlésünket.
Mert éhezzük az élményt
Az élmények és azok megélése életünk részei, alapvető igényünk van ezekre a kezdetektől fogva, és lesz a jövőben is. A szórakoztatás iparággá alakult, a nagy cégek pedig rájöttek, hogy óriási és kiaknázatlan lehetőség van abban, ha az élményvágy kielégítése mellett létrehozzák és táplálják is mindazt. Egyebek mellett a Netflix leghatalmasabb potenciálja pont ebben áll. Kapcsolatba lép velünk, kihasználja a kényelem iránti igényünket, majd tűélesen analizált preferenciáink alapján táplálja a vágyainkat: az algoritmusa segít, hogy azt a tartalmat nézzük, úgy, és leginkább akkor, ahogyan azt mi nézőként szeretnénk.
A következő ábra azt mutatja be, hogy az élmények sokkal fontosabbak a fogyasztóknak, mint egy adott termék, vagy szolgáltatás. Ha a termék, vagy szolgáltatás használata nem okoz élményt, akkor ezek legtöbbször feleslegessé válnak a felhsználók számára:
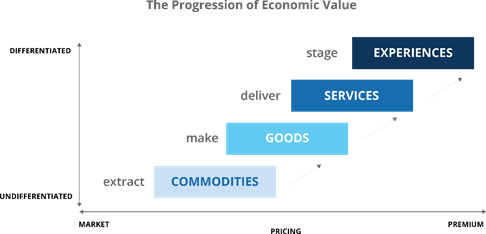
A fogyasztók már nem csak árukat és szolgáltatásokat keresnek, hanem főként élményeket (via)
Az amerikai cég több területen is alkalmazza a mesterséges intelligenciát. Ilyen a streaming minőség meghatározása, a filmszerkesztési utómunkálatok, a filmgyártás helymeghatározása, a saját gyártású filmek létrehozása, vagy a tartalom ajánlások személyreszabása - itt mind MI által átszőtt megoldásokat találhatunk. Az utóbbi években ez az ajánlási- és személyre szabási rendszer lett a vállalat egyik legnagyobb értékesítési erőssége, ezért a következőkben ezt a megoldást vizsgáljuk.
Személyre szabás: a Netflix fő versenyelőnye
Felmerült már benned, hogy miért ajánl minden egyes filmnézés előtt különböző filmeket a Netflix? Vagy az, hogy éppen hogyan profilozza a több mint 100 millió előfizetőjét? Az adat kardinális tényező, és a kérdés megválaszolásának kulcsa is az adatainkban keresendő. A Netlixnél ugyanis sosem tagadták, rengeteg információt gyűjtenek rólunk:
„Tudjuk, hogy a nap melyik órájában nézed a tartalmat, hogy mennyi ideig nézted, tudjuk, hogy mit néztél előtte, mit néztél utána, hogy a számítógépeden, az okostelefononodon vagy tableten nézted-e, illetve az is, hogy melyik profilból nézted. Nagyon sok információnk van.”– mondta Todd Yellin, a Netflix termékmenedzsment igazgatója.
Minden ilyen megoldás tulajdonképpen egy üzleti problémára vezethető vissza. A „probléma” az, hogy a Netflix hatalmas tartalomkönyvtárral rendelkezik, amely dinamikusan változik, és a felhasználó számára mindez túl bőséges kínálatot jelenthet. A felhasználó nem akar csalódni, előfizetéséért cserébe az érdeklődésének megfelelő tartalmat akarja megtalálni, azaz azt a személyes élményt keresi, amit a lineáris televíziózás során nem feltétlenül kaphat meg. A Netflix ajánlási rendszere pont erre a problémára ad megoldást, és ezt aknázza ki.
A Netflix már évekkel ezelőtt arra törekedett, hogy minden filmet adatokra lehessen bontani, a filmproducereknek pedig fizettek is, hogy minél pontosabban tudják az adott filmet bekategorizálni. Alexis Madrigal technológiai újságíró is alátámasztja azt, hogy a Netflix könyvtárában lévő összes terméket hatalmas címkék sorozatára bontják, amelyek nemcsak helyekre vagy a szereplőkre vonatkoznak, hanem sokkal szélesebb kategóriákra is, mint például "erkölcs" vagy "érzelmi hatás". A fő algoritmusuk tehát nagyon finoman meghatározott, több mint 27 000 (!) mikro-műfaj alapján működik. Ez a megoldás lehetővé teszi a cég számára, hogy nagy pontossággal testre szabhassák a javasolt filmeket vagy sorozatokat, és így nekünk tetsző ajánlásokat kaphassunk. A folyamatos fejlesztésre való igényt bizonyítja, hogy 2016-ig „csak” földrajzi, életkori és nemi adatok szerint szegmentáltak, mára pedig globálisan körülbelül 2000 preferencia- és ízlésközösséget, úgynevezett klasztert generáltak. Attól függően pedig, hogy milyen az ízlésünk, egyfajta virtuális közösséghez tartozunk, amelyben a tartalom is dinamikusan változik interakcióink hatására. A személyre szabhatóság alapja tehát a tartalom címkézése és a virtuális „közösségek” kialakítása.
 Vajon milyen hatással vannak az algoritmusok a választásunk szabadságára? (via)
Vajon milyen hatással vannak az algoritmusok a választásunk szabadságára? (via)
Valójában a Netflix fő algoritmusa sokkal több, mint egy elektronikus „műszer”, amely korábbi döntések alapján minden előfizető számára külön címeket ajánl. Ez egy felfoghatatlanul komplex rendszer, ami a datascience és a gépi tanulás eszközeivel folyamatosan átalakítja a látszólag kaotikus viselkedésünket ismétlődő és ezért kiszámítható mintákká. A Netflix korántsem csak streaming filmeket és TV-műsorokat szolgáltat, hanem megpróbálja kielégíteni azokat a vágyainkat, amelyekről esetleg mi magunk sem tudunk.
A rendszer négy különféle módszerre épül:
- a felhasználók személyes profiljára: tehát korábbi választásainkra, az ötcsillagos visszacsatolási és besorolási rendszerre, ahol értékelni tudjuk a filmeket, a görgetési tevékenységünkre és a megtekintési szokásainkra, azaz az interakcióinkra;
- az együttműködési szűrésre a „ügyfélklaszterek” révén: ez egy ajánlási technika, amely a felhasználói visszajelzéseken alapul
- a címkéző rendszerre, amely szorosan összekapcsolódó filmek (pl. ugyanazon rendező által készített vagy ugyanazon műfajú filmek) csoportosítását célozza
- a Netflix saját kereskedelmi prioritásaira.
Az algoritmus gyakorlati működése úgy elemezhető, hogy amikor például egy Netflix felhasználó a „Stranger Things” című sorozatot nézi, akkor az interakció során elemzett adatnyomok betáplálódnak a PRS-be (Personalization and Recommendation System röviden: PRS), amely meghatározza a felhasználó valószínű viselkedési és megfigyelési mintáját. Ez azt eredményezi, hogy a felhasználó a következő bejelentkezésekor ajánlásokat kap. Ez a folyamat mindig folytatódik, és a rendszer aszerint módosítja az ajánlásokat, ahogyan a felhasználó viselkedett a platformon. Minden egyes alkalommal, amikor a felhasználó bejelentkezik, ezen minták alapján talál egy újból generált és meghatározott tartalomkatalógust. A PRS rendkívül adaptív, folyamatosan alkalmazkodik az új interakciókhoz, éppen ezért a felhasználó számára mutatott tartalom egyre inkább egy olyan felhasználói profilt állít elő, amely sokkal inkább a PRS saját logikájára támaszkodik, mint a felhasználó valódi és autonóm nyílt interakcióira. Tehát az, amit mérnek, nem a felhasználó spontán és szándékos elkötelezettsége. Ez az algoritmikus determinizmus hozza létre azt, amit Cheney-Lippold algoritmikus identitásnak nevez.
„Ezt az identitást olyan cégek generálják, amelyek feltérképezik, összehasonlítják, majd algoritmikusan értelmezik a felhasználók adatait annak érdekében, hogy megértsék a felhasználók identitását, de nem a tényleges személyiségét, hanem digitális identitás vagy profil formájában.”
 A profilunk alapján mutatják be nekünk a filmeket reklámozó képeket (via)
A profilunk alapján mutatják be nekünk a filmeket reklámozó képeket (via)
Betekintő: a kép, amely többet mond minden szónál
Hiába egy mesterien kidolgozott ajánlási rendszer, ha végsősoron a felhasználó nem kattint. A Netflix erre is kidolgozott egy megoldást, mégpedig a filmeket bemutató miniatűrök (angolul: „thumbnail”-ek) generálása és személyre szabása révén.

Egy sorozat megannyi thumbnail-je, ízlésünktől függően (via)
Minden egyes filmet vagy sorozatot ugyanis a tartalomkönyvtáron belül úgynevezett indexképekkel reklámoznak. A cél, hogy minden műsorhoz olyan képek társuljanak, amelyek kiemelik az egyes tagok szempontjából releváns vizuális tartalmat, és így biztosan elköteleződést, tehát kattintást vált ki. Minden esetben több száz fajta képet rendelnek a film bemutatására, amelyből az előfizetőknek mindig a legrelevánsabbat használják fel. Mindegyik képpel tehát másfajta személyiség típusokat, különböző ízléscsoportokat próbálnak megszólítani, vagy ahhoz hangolják a képet, hogy milyen más filmeket és sorozatokat néztünk meg korábban.
Elég egyértelműnek látszik, hogy a Netflix adatainak kombinációja, algoritmikus személyre szabása és kormányzása, illetve hatalmas tartalomkönyvtára mind-mind olyan tényezők, amelyek a felhasználókat még inkább a képernyő elé fogják vonzani. Az igény adott a közönség részéről – és láthatóan a Netflix erre tökéletesen reagál.
Fontos azonban látnunk, hogy bármilyen kifinomult is a Netflix címkézési folyamata, az előzetes preferenciáinkból és interakcióinkból kiszűrt metaadatok és együttműködési szűrők nem képesek teljes mértékben utánozni az egyedi ízlést. Ehelyett tűélesen analizált és megalapozott döntéseket hoznak, amelyek az esetek többségében valóban személyre szabott ajánlást jelent. Ez persze a legtöbb esetben hűen tükrözi valódi igényünket, de mivel matematikai képleten működő rendszerekről beszélünk, a folyamaton belül mindig érdemes a végső emberi döntéshozással, mint elemmel számolni. Valódi és teljes személyre szabottságról akkor beszélhetnénk, ha MI a gondolatunkat is olvasná, és azokat a váratlan emberi döntéshozásból adódó fordulatokat is meg tudná fejteni, ami bennünk megy végbe. Ugyanis a gép sosem fogja tudni, hogy két hét teljes horror „filmmaraton” után mikor vágyunk egy kis romantikára, vagy netalántán vígjátékra. Az algoritmusok – jelenlegi fejlettségi szintükön – sosem lesznek képesek fontos döntéseket hozni helyettünk, mivel a számítógépes algoritmusoknak nincsennek érzelmeik, sem ösztöneik.
További olvasmány: Kevin McDonald & Daniel Smith-Rowsey (2016): The Netflix Effect: Technology and Entertainment in the 21st Century.
A bejegyzés szerzője Gyenes Donát, a BME KomMédia mesterszakos hallgatója.







 (
(